



Van data naar beslissingen: vergroot je impact met moderne business intelligence
Zet ruwe data om in heldere beslissingen met moderne BI: één versie van de waarheid, duidelijke KPI’s en dashboards die je sneller laten bijsturen. Je ontdekt de essentials van architectuur en governance (van ETL/ELT en stermodellen tot AVG), de nieuwste tools en trends voor 2025 (AI/augmented, embedded en realtime) en concrete use cases voor finance, sales, marketing en operations. Met een pragmatische aanpak start je klein, vermijd je valkuilen en realiseer je snel meetbare impact.

Wat is business intelligence (BI) en waarom het telt
Business intelligence (BI) is de manier waarop je ruwe data omzet in begrijpelijke inzichten die direct helpen bij betere beslissingen. Met BI verzamel je gegevens uit verschillende systemen, maak je ze schoon en consistent, modelleer je ze logisch en zet je ze om in dashboards en rapportages die antwoord geven op je belangrijkste vragen. Denk aan heldere KPI’s (kritieke prestatie-indicatoren) die laten zien hoe je verkoop, marge, voorraad, marketing of service presteren, zonder eindeloos te hoeven zoeken in losse spreadsheets. BI draait om inzicht in wat er is gebeurd en wat er nu gebeurt, zodat je sneller kunt bijsturen; het verschilt daarmee van data science, dat vooral voorspelt wat er kán gebeuren.
Waarom dit telt? Omdat je met BI sneller beslissingen neemt, risico’s vermindert en kansen eerder ziet, bijvoorbeeld door vroegtijdig klantverloop te detecteren, inefficiënte processen te spotten of marketingbudget slimmer te verdelen. Je creëert één versie van de waarheid met eenduidige definities, waardoor teams in sales, finance en operations op dezelfde cijfers sturen. Self-service dashboards geven je direct toegang tot actuele informatie, zonder te wachten op een rapport. Dat bespaart tijd, verhoogt de datakwaliteit en versterkt een cultuur van meten en verbeteren, zodat je organisatie wendbaarder en winstgevender wordt.
Definitie en kernbegrippen (data, KPI’s, dashboards)
In BI zijn data de ruwe feiten uit je systemen: transacties, webbezoeken, voorraadstanden. Zonder context zeggen ze weinig, daarom modelleer je ze in dimensies (wie, wat, waar, wanneer) en maatstaven (hoeveel, bedrag, aantal). KPI’s zijn de kritieke prestatie-indicatoren die je doelen meetbaar maken, zoals omzetgroei, marge of churn; je definieert ze eenduidig en koppelt ze aan drempelwaarden.
Dashboards vormen de visuele laag waarin je KPI’s en trends samenkomen, met filters, drill-down en tijdreeksen, zodat je van overzicht naar detail kunt gaan. Goede BI draait om betrouwbare data, consistente definities en snelle toegankelijkheid, zodat je op basis van dezelfde cijfers beslissingen neemt en je prestaties continu kunt volgen en verbeteren.
BI vs. data analytics en data science: verschillen in praktijk
BI draait om het produceren van betrouwbare, gestandaardiseerde inzichten voor de hele organisatie: goed gedefinieerde KPI’s, consistente definities en dashboards die je dagelijks gebruikt om prestaties te volgen en bij te sturen. Data analytics is breder en vaak exploratief: je graaft in data om oorzaken te vinden, segmenten te ontdekken of hypotheses te testen, bijvoorbeeld via ad-hoc analyses of A/B-tests. Data science gaat een stap verder met voorspellende en voorschrijvende modellen, zoals forecasting, churnmodellen of optimalisatie met machine learning; de uitkomst is vaak een model dat via een API, app of proces continue beslissingen ondersteunt.
In de praktijk werk je met BI voor stabiele rapportages, met analytics voor diagnose, en met data science wanneer je gedrag wilt voorspellen en automatisch wilt sturen.
Voordelen voor je organisatie (snellere besluiten, minder risico, meer rendement)
Met BI neem je sneller en met meer vertrouwen beslissingen, omdat je één versie van de waarheid hebt: dezelfde definities, actuele data en duidelijke KPI’s die voor iedereen gelden. Dashboards en alerts laten je direct zien waar het mis of juist goed gaat, zodat je sneller kunt ingrijpen, kansen pakt en geen tijd verliest aan het verzamelen van losse spreadsheets. Je verkleint risico’s door vroegtijdige signalen op te vangen, zoals dalende conversies, oplopende kosten of voorraadaanvallen, en door compliance-eisen beter te borgen met traceerbare data en toegangsrechten.
Meer rendement volgt doordat je campagnes scherper stuurt, prijzen en marges optimaliseert, verspilling vermindert en processen slimmer inricht. Tegelijk bespaar je tijd en geld, omdat teams zelf antwoorden vinden zonder eindeloze ad-hoc rapportverzoeken.
[TIP] Tip: Verbind BI met strategie; definieer kern-KPI’s en automatiseer updates.
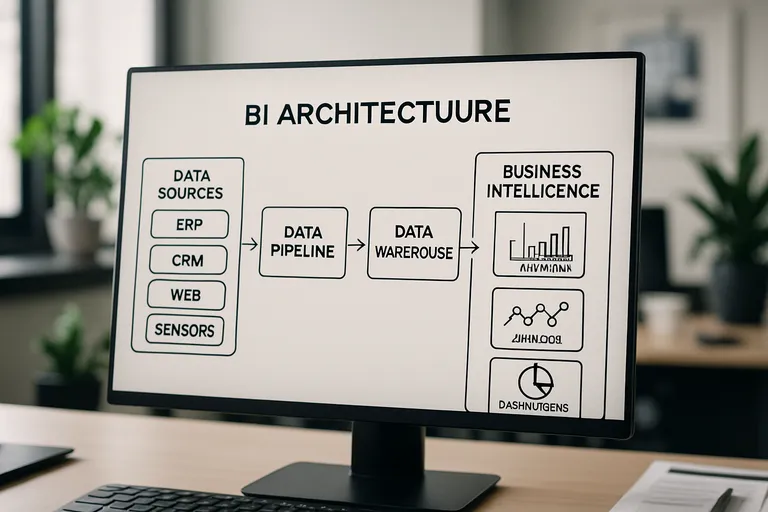
De BI-architectuur in het kort
Een BI-architectuur brengt je data van bron tot besluit in één samenhangende keten. Je start bij databronnen zoals ERP, CRM, web en sensoren, waarna je via een data-pipeline gegevens extraheert, transformeert en laadt (ETL/ELT) en direct datakwaliteit bewaakt. Voor opslag kies je meestal een data warehouse voor gestructureerde, rapportageklare data en eventueel een data lake voor ruwe, onbewerkte datasets. Bovenop die laag bouw je een logisch datamodel, vaak in een stermodel met feiten en dimensies, zodat analyses snel en eenduidig zijn. Een semantische laag legt je definities en KPI’s vast en maakt self-service mogelijk zonder dat iedereen eigen rekenregels verzint.
De visualisatielaag levert dashboards, rapportages en ad-hoc analyse met goede performance door indexing en caching. Governance en security regelen autorisaties, datatoegang op rij- en kolomniveau en voldoen aan de AVG, terwijl metadata en lineage laten zien waar cijfers vandaan komen. Steeds vaker gebruik je cloudplatformen voor schaalbaarheid, kostenbeheersing en realtime stromen, zodat je inzichten actueel blijven en je sneller kunt sturen.
Databronnen en integratie (ETL/ELT) en datakwaliteit
Je BI-landschap begint bij databronnen zoals ERP en CRM, webanalytics, spreadsheets, API’s en soms streaming-events. Met ETL transformeer je data vóór het laden, terwijl je bij ELT eerst alles in je data warehouse of lakehouse laadt en daar de transformaties uitvoert. Zo kun je schaalbaar werken en snel nieuwe vragen beantwoorden. Betrouwbare integratie draait om robuuste pipelines met scheduling, foutafhandeling en change data capture, zodat wijzigingen in bronsystemen netjes doorstromen.
Datakwaliteit borg je met regels voor volledigheid, nauwkeurigheid, consistentie en actualiteit, plus data profiling om afwijkingen te spotten. Denk aan deduplicatie, validaties op referentietabellen en heldere masterdata-definities. Door lineage te bewaren en kwaliteit te monitoren met alerts, weet je waar cijfers vandaan komen en kun je issues snel herstellen voordat ze je dashboards raken.
Dataopslag kiezen: data warehouse vs. data lake
Een data warehouse is geoptimaliseerd voor betrouwbare rapportages: je zet data om naar een gestandaardiseerd model (schema-on-write), bewaakt definities en krijgt snelle, consistente queries voor je dashboards en KPI’s. Een data lake slaat ruwe, gestructureerde én ongestructureerde data op (schema-on-read), is goedkoper per gigabyte en ideaal voor exploratie, data science en machine-learning, inclusief grote bestanden en streaming.
Kies vooral een warehouse als je stabiele stuurinformatie en strakke governance nodig hebt; kies een lake wanneer je flexibiliteit, historiek en experimenten belangrijk vindt. In de praktijk combineer je beide in een lakehouse: schaalbaar opslagformaat met transactionele tabellen, waardoor je BI-rapportages en advanced analytics op dezelfde bron kunt draaien zonder dubbele data en met betere datakwaliteit.
Visualisatie en self-service (dashboards, rapportages, ad-hoc analyse)
Met visualisatie zet je gegevens om in heldere verhalen: grafieken, kaarten en tabellen die snel laten zien wat belangrijk is, met kleuren en context die niet misleiden. Dashboards geven je realtime overzicht van KPI’s, rapportages bieden vaste, herhaalbare detailinformatie en ad-hoc analyse laat je vrij onderzoeken, filteren en drill-downen tot op transactie-niveau. Self-service werkt pas echt als je met een gedeelde semantische laag en gecertificeerde datasets werkt, zodat iedereen dezelfde definities gebruikt.
Je borgt dat met rechten op rijniveau, dataverse versies en duidelijke naming. Let op performance met aggregaties en cachings, en verhoog adoptie met alerts, uitleg bij KPI’s en mobiele weergaven. Zo maak je data toegankelijk zonder controle te verliezen.
[TIP] Tip: Focus op één bron van waarheid; standaardiseer KPI-definities organisatiebreed.

Tools, trends en use cases in 2025
In 2025 draait je BI-stack om schaal, snelheid en slim gebruiksgemak. Tools als Power BI, Tableau, Qlik en Looker combineren een sterke semantische laag met AI-features zoals natural language vragen, automatische insights en slimme uitleg bij afwijkingen. Je kiest vooral op basis van je cloud-ecosysteem, governance-eisen, kosten en skills in je team. Lakehouse-architecturen en open formaten maken het makkelijker om BI en data science op dezelfde bron te laten landen, terwijl realtimestromen en change data capture zorgen voor up-to-date dashboards.
Embedded BI brengt inzichten direct in je CRM of app, en headless/metrics layers leveren consistente KPI’s in elk kanaal. Praktische use cases blijven leidend: finance versnelt de maandafsluiting en cashflow-forecasting, sales stuurt op pijplijnkwaliteit en churn, marketing optimaliseert campagnes en CAC, operations verlaagt doorlooptijd en faalkosten, supply chain verbetert voorraadrotatie en OTIF, en HR monitort verloop en verzuim. Met goede governance, row-level security en datacontracten houd je snelheid zonder de controle te verliezen.
Populaire BI-tools en wanneer je welke kiest
Onderstaande tabel vergelijkt populaire BI-tools voor business intelligence (BI) in 2025: hun sterktes, typische omgevingen en wanneer je welke kiest.
| Tool | Sterktes in het kort | Typische omgeving/stack | Kies wanneer |
|---|---|---|---|
| Microsoft Power BI | Sterke datamodellering (DAX/Power Query), integratie met Microsoft 365/Azure, governance (RLS, lineage), goede prijs/waarde; fabric-integratie. | Microsoft-centrisch (Azure Synapse/SQL, Office 365, Teams); SaaS of on-prem via gateway. | Je vooral in de Microsoft-stack zit en brede self-service wilt combineren met centrale governance en schaalbaarheid. |
| Tableau | Uitstekende visuele analyse en dataverkenning, rijke interactieve dashboards, sterke community en extensies. | Heterogene omgevingen; SaaS (Tableau Cloud) of on-prem (Tableau Server) met brede connectoren. | Datavisualisatie en ad-hoc analyse prioriteit heeft en teams snel inzichten willen ontdekken en delen. |
| Qlik Sense | Associative engine voor vrij navigeren, sterke in-memory performance, governed self-service, alerts/AI-assist. | Gemengde databronnen; SaaS of client-managed; krachtige scripting en incremental loads. | Gebruikers snel willen zoeken/filtreren over veel tabellen en je robuuste, schaalbare apps met strakke governance nodig hebt. |
| Looker (Google Cloud) | Centraal gedefinieerde metrics via LookML, live query op het warehouse, sterke BigQuery-integratie, embedded BI. | Moderne cloud-DWH (BigQuery, Snowflake, Redshift); volledig SaaS. | Je een enkele bron van waarheid voor KPI’s wilt, zwaar op GCP/BigQuery leunt en governed self-service plus embedded nodig hebt. |
De keuze draait om stack-fit (Microsoft, GCP of gemengd), governance en het primaire gebruik (exploratie vs. gestandaardiseerde KPI’s). Alle vier leveren enterprise-BI; het verschil zit vooral in modellering, integratie en gebruikerservaring.
Power BI past goed als je al op Microsoft 365 en Azure draait: sterke integratie met Teams, Excel en Azure Synapse, scherpe prijs en brede self-service. Tableau kies je wanneer visuele flexibiliteit en dataverkenning voorop staan; het blinkt uit in interactieve visualisaties en designvrijheid. Qlik is sterk in associative analytics: je ontdekt verbanden buiten vooraf gedefinieerde schema’s, handig voor exploratie over veel databronnen.
Looker (Looker Studio/Looker) kies je als je een centrale metrics-laag wilt met strakke governance en consistente definities over apps heen, vooral in Google Cloud. Let bij je keuze op bestaande skills, licentiemodel, governance (row-level security, auditing), performance op je data-platform (Snowflake, BigQuery, Databricks) en embedded-mogelijkheden om inzichten direct in je workflows te brengen.
Belangrijke trends: AI-gestuurde inzichten, augmented en embedded BI, realtime
AI-gestuurde inzichten tillen je BI naar een hoger niveau met automatische anomaliedetectie, trendverklaringen en natuurlijke taal waarmee je vragen stelt en direct visualisaties terugkrijgt. Augmented BI versnelt je werk door slimme suggesties voor datamodellering, KPI’s en grafiekkeuzes, en helpt bij data-preparatie met automatische joins, verrijking en kwaliteitschecks. Embedded BI brengt inzichten naar waar je werkt: in je CRM, ERP of eigen app, compleet met een gedeelde metrics-laag zodat definities overal gelijk zijn.
Realtime analytics maakt je dashboards actiegericht dankzij streamingdata en change data capture, waardoor je binnen minuten kunt bijsturen. Succes hangt af van goede governance en datakwaliteit, anders verpak je ruis in een mooie grafiek. Met deze trends maak je beslissingen sneller, consistenter en dichter op de operatie.
Use cases per afdeling met sturende KPI’s (finance, sales, operations, marketing)
In finance stuur je met BI op cashflow, marge en voorspelbare liquiditeit door nauwkeurige omzet- en kostenreconciliatie, een korte debiteurentermijn en tijdige waarschuwingen bij budgetafwijkingen. In sales volg je pijplijnkwaliteit, win-rate, gemiddelde dealwaarde en doorlooptijd, zodat je sneller prioriteiten kunt stellen, focus houdt op kansrijke leads en klantverloop (churn) vroeg signaleert. In operations maak je prestaties zichtbaar met doorlooptijd, leverbetrouwbaarheid, eerste-keur (aandeel zonder herstelwerk) en voorraadrotatie, waardoor je bottlenecks vindt en verspilling vermindert.
In marketing koppel je kanalen aan concrete uitkomsten met kosten per acquisitie, campagnerendement en klantwaarde, zodat je budget naar de beste bronnen verschuift. Door deze KPI’s in consistente dashboards te combineren, zie je realtime waar je moet bijsturen en boek je sneller resultaat.
[TIP] Tip: Integreer BI met GenAI; gebruik natuurlijke taal voor analyses.

Succesvol starten met BI: aanpak en valkuilen
Begin met het waarom: formuleer concrete businessvragen en koppel daar meetbare KPI’s aan, zodat je precies weet welke beslissingen je wilt versnellen. Breng vervolgens je databronnen in kaart en ontwerp een eenvoudig, herbruikbaar datamodel met eenduidige definities. Start klein met een MVP-dashboard voor één proces of afdeling, lever binnen 6-8 weken waarde en werk iteratief op basis van feedback. Regel governance vanaf dag één: wijs een product owner, data owners en stewards aan, leg definities vast in een semantische laag en borg privacy en beveiliging (bijv. row-level security en AVG-richtlijnen). Investeer in datakwaliteit met duidelijke validaties en monitoring, anders meet je schijnnauwkeurigheid.
Zorg voor adoptie: train gebruikers, creëer een netwerk van BI-champions en documenteer context en rekenregels in de dashboards. Let op valkuilen zoals tool-first beslissen, scope creep, silo-oplossingen, te complexe modellen en het overslaan van testen en performance-tuning. Meet succes met heldere outcome-metrics (tijdswinst, minder fouten, hogere marge) en onderhoud een BI-backlog met prioriteiten. Door gefaseerd te bouwen, grip te houden op definities en gebruikers actief mee te nemen, maak je BI duurzaam, schaalbaar en direct sturend in de dagelijkse operatie.
Stappenplan van strategie tot uitrol (businessvragen, datamodel, MVP-dashboard)
Begin met het scherpstellen van je businessvragen: welke beslissingen wil je versnellen en welke KPI’s horen daarbij. Vertaal dat naar concrete use cases en prioriteer op impact en haalbaarheid. Inventariseer je databronnen, bepaal datakwaliteit en ontwerp een eenvoudig, schaalbaar datamodel (bijv. een stermodel) met eenduidige definities in een semantische laag. Bouw vervolgens een MVP-dashboard voor één proces of afdeling dat direct antwoord geeft op de topvragen, inclusief filters, drill-down en uitleg bij KPI’s.
Test op datanauwkeurigheid, performance en security (row-level security, AVG), verzamel feedback en verbeter in korte iteraties. Regel governance en eigenaarschap, plan training voor gebruikers en koppel succes aan meetbare uitkomsten, zodat je na de MVP gecontroleerd kunt opschalen naar andere teams.
Veelgemaakte fouten en hoe je ze voorkomt (tool-first, scope creep, silo’s)
Tool-first voorkomen: begin met je belangrijkste beslissingen en KPI’s, vertaal die naar eisen voor data, governance, security en kosten, en toets tools pas daarna met een proof-of-value op je eigen dataset. Scope creep voorkom je met een scherp MVP, duidelijke acceptatiecriteria, timeboxed sprints en een backlog waar nieuwe wensen naartoe gaan.
Silo’s breek je af door een multidisciplinair team te vormen en één semantische/metrics-laag, datacatalogus en gezamenlijke definities te hanteren. Wijs data owners aan, automatiseer datakwaliteitschecks en communiceer releases, zodat iedereen op dezelfde cijfers stuurt en je tempo behoudt.
Datamodellering en KPI-ontwerp (star schema, maatstaven en dimensies)
Een goed BI-model begint bij een duidelijk “grain”: het laagste detail waarop je feiten vastlegt, zoals orderregel of dag. In een star schema staan die feiten met maatstaven (bijv. omzet, aantallen, kosten) in een fact-tabel, omringd door dimensies met context zoals klant, product, tijd en kanaal. Maatstaven definieer je eenduidig en bepaal je aggregatiegedrag: optelbaar, semi-optelbaar of niet-optelbaar. Dimensies krijgen logische hiërarchieën (jaar > kwartaal > maand) en consistente sleutels; historische wijzigingen kun je vastleggen zodat je analyses kloppen door de tijd heen.
KPI’s ontwerp je bovenop deze basis: formule, drempelwaarden, interpretatie en eigenaar, inclusief tijdslogica zoals groei versus vorig jaar en rolling averages. Door definities te borgen in een semantische laag zorg je dat filters en berekeningen overal hetzelfde werken en dashboards snel en betrouwbaar zijn.
Governance, security en privacy (autorisaties, AVG, datatoegang)
Goede governance betekent dat je duidelijke spelregels vastlegt: wie is eigenaar van welke data, wat betekenen je definities en waar vind je ze terug in een datacatalogus. Security richt je in volgens het least-privilege-principe met autorisaties op rijniveau (row-level security), scheiding van taken, en versleuteling van data in rust en tijdens transport, aangevuld met veilig beheer van wachtwoorden en sleutels. Voor privacy voldoe je aan de AVG met dataminimalisatie, een rechtmatige grondslag, bewaartermijnen, en procedures voor inzage en verwijdering; bij risicovolle verwerkingen voer je een DPIA uit en pas je pseudonimisering of anonimisering toe.
Je regelt datatoegang via rollen en goedkeuringsflows, bewaakt alles met auditlogs en monitoring, en borgt kwaliteit en herkomst met data-contracts en lineage. Regelmatige reviews houden je controle actueel.
Veelgestelde vragen over bi intelligence
Wat is het belangrijkste om te weten over bi intelligence?
Business intelligence (BI) is het vertalen van ruwe data naar bruikbare inzichten via betrouwbare datasets, KPI’s en dashboards. BI ondersteunt snellere, beter onderbouwde besluiten, vermindert risico’s en verhoogt rendement, met self-service analyses voor teams.
Hoe begin je het beste met bi intelligence?
Begin met bedrijfsdoelen en kritieke vragen, definieer KPI’s, inventariseer databronnen en datakwaliteit. Ontwerp een eenvoudig stermodel, bouw een MVP-dashboard, kies een warehouse- of lake-architectuur, automatiseer ETL/ELT, borg governance/AVG, en train stakeholders.
Wat zijn veelgemaakte fouten bij bi intelligence?
Valkuilen: tool-first denken, onvoldoende datadefinities en kwaliteitscontroles, scope creep, silo’s zonder centrale waarheid, te complexe dashboards, vergeten change management en training, zwakke autorisaties/AVG, en geen duidelijke eigenaar voor KPI’s, datamodel en lifecycle.